by Nicholas Phelps
Preparing for a Java interview can be stressful, and you’ll need to plan for several eventualities for it be a success. Fortunately, one of Pearson Frank’s top Java recruiters has put together the following tips to help you ace your next Java developer interview.
Do your Java homework
First and foremost, do your research on the latest trends and techniques involving the Java programming language. The software development industry is continually changing, so keep up to date with all the latest goings-on.
Interviewers want to know if you have a clear-cut understanding of software development principles. But the focal point of the interview will be Java itself, its standard libraries, relevant frameworks, and other tools used alongside the programming language.
Strong working knowledge of Java should be enough to get you through the first stages of an interview. But if you want to stand out from the crowd, focus your answers on the frameworks and databases the business deploys on their development floor.
If you’re struggling to pinpoint this information, read through the job specification, take a look at the company website, or get in touch with the recruiter who arranged the interview. Every detail that makes you more memorable could secure the role, so do everything you can to brush up on the right Java skills.
Make sure you understand the entire interview process
No two interviews are the same. Every company has a different way of doing things. Be sure to have a full understanding of the entire interview process, what you’re likely to be asked, and if there will be any technical elements.
You need to plan for every eventuality. Technical tests, coding reviews, and written exams all require different preparation techniques, so make sure you receive a complete brief outlining all aspects you’re likely to face in the interview.
Many businesses operate a two-stage interview policy which means you may be invited back to perform a technical assessment on a different day.
What you need to remember is although these situations can seem stressful, it gives businesses the opportunity to see how developers solve problems and react under pressure, and also benchmark your performance against the job specification.
Do more homework
This time on the company itself. Find out about the industry they operate in and the applications they develop. Most interviewers will take the time to ask what you know about their business, so be prepared for any questions they’re likely to throw your way.
A simple Google search should tell you whether they’ve won industry awards, their reputation in the sector, and recently featured in any positive PR campaigns. Demonstrating all of this extra knowledge shows your enthusiasm about the business you’re joining, which can stand out in the mind of an interviewer.
Remember to ask questions
Interviews are the perfect place for you to express any apprehensions you have about the company looking to acquire your services, so have a list of questions ready should the opportunity arise.
One of the common questions to ask in during a Java developer interview is what tech stack they use on their development floor. Every business is different, and by finding out this info before landing a role, you can improve your current skill level and hit the ground running on day one should you be offered the position.
You should also ask whether the interviewer has any concerns about your application. If they do, having strong answers to alleviate their reservations can help ease the way to the next stage of the interview.
This is also the perfect opportunity for you to ask about the next steps in the interview process. Depending on the response of the interviewer, you should be able to decipher how well you’ve done and whether you’ll be asked to attend the next stage.
The don’ts of an interview
We’ve covered the points that can help you walk into an interview and leave the room with a job, but here are a few pointers to help avoid a complete disaster.
When asked if you have any questions, do your best not to bring up your salary expectations as your first port of call. There is such a thing as bad timing, and although it’s something you’ll definitely want to ask, a technical interview isn’t always the right scenario to have this conversation.
Finding the right opportunity to pose those questions can be tricky, so if you get the chance to speak to a recruiter or HR professional within the business this could be the perfect time to ensure your salary expectations are met and the entire process runs smoothly.
You’ll also need to make sure you arrive on time. Turning up five minutes after your interview was scheduled can be extremely off-putting for an interviewer, so my advice is that it’s better to be an hour early than arrive late.
Taking note of these tips will help you breeze through your next Java interview. Remember to brush up on all your skills, plan ahead for technical tests, monitor the business performance, and you should land your dream Java role.
Nicholas Phelps is a Java team lead at niche IT recruiter Pearson Frank. Overseeing the hiring to Java developers, he has over 4 years’ experience in the Java marketplace.
 Having a child is one of the most memorable moment you can experience. Parents have a huge responsibility with this new life and it starts right away when they have to choose the name. Our name is something that we keep for life (most of the times), so it needs some careful consideration. With literally thousands of names to choose from, how about using some Java technology to help us?
Having a child is one of the most memorable moment you can experience. Parents have a huge responsibility with this new life and it starts right away when they have to choose the name. Our name is something that we keep for life (most of the times), so it needs some careful consideration. With literally thousands of names to choose from, how about using some Java technology to help us?
Yes, I wrote a small Java application to help me choose my baby name!
Requirements
First of all, we have to define some rules!
Basic Rules
- A short name (but not too short)
- In the first half of the alphabet
- Without special characters
A short name, so it easy to call him. In the first half of the alphabet, because in Portugal we have this stupid rule where kids get seated in the classrooms in alphabetic order, so letters in the end of the alphabet get to sit in the end of the room! And finally, a name without special characters (we have a few in Portugal), to be easier for foreign people to use.
Advanced Rules
- Exists in at least three languages (Portuguese, Spanish and English)
- Sounds and Writes the same in all three languages
To cover the fact that I was born in a Spanish speaking country, that we live in Portugal and English for the globalization.
Constraints
There are also some constraints. In Portugal, you cannot use any name you want. You need to pick the name from an approved list of names. Of course, this is a comprehensive list of names that covers all common names. It is mostly used to avoid giving a stupid name to your kid. If your curious about it, check the list here.
Implementation
Basic Rules are Easy
After grabbing the data in the file and use some Java 8 Streams:
| .filter(Name::isAllowed)
.filter(Name::isNotFemale)
.filter(Name::withoutSpecialChars)
.filter(n -> n.between(3, 7))
.filter(n -> n.notStarstWith("N", "O","P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z")) ; |
(Yes, I’m lazy with regular expressions)
Advanced Rules are more Interesting
Beider-Morse Phonetic Matching
When searching for a way to determine if a word or a name exists in another language and sounds the same, I came across with the Beider-Morse Phonetic Matching.
The main objective of Beider-Morse Phonetic Matching consists in recognizing that two words are written in a different way actually can be phonetically equivalent, that is, they both can sound alike. But unlike soundex methods, the “sounds-alike” test is based not only on the spelling but on linguistic properties of various languages.
How?
It tries to guess the language of the word following specific language rules and then calculates a phonetic value for that word. For instance:
- tsch, final mann and witz are specifically German
- final and initial cs and zs are necessarily Hungarian
- cz, cy, initial rz and wl, final cki, letters ś, ł and ż can be only Polish
And then a phonetic value is calculated:
| Original | Phonetic Value | Example |
|---|
| tz | ts | Fitzgerald |
| c | s | circle |
| cc | ks | success,accent |
| gh | (g|f|w) | burgh|tough|bough |
| kn | n | knight |
| mc | mak | McDonald |
The Commons Coded project has an implementation of the Beider-Morse Phonetic Matching algorithm. Try it out and play with it.
Rosette API
The Rosette API is a Text Analysis Toolkit, that provides multiple services to perform text analysis. They also have a Name Translation service with a REST endpoint that you can use to feed in names and the desired language and return the right translation with a confidence score. Their API is useful to double check results obtained with the Beider-Morse Phonetic Matching.
They have fantastic support, providing libraries to integrate with their API’s in multiple languages and also a lot of samples you can use. Check their Github repo here.
behindthename.com
The Behind the Name website provided with the etymology and history of first names, plus a comprehensive list of names and what languages do they exist. On top of that, they also provide an API to check that information, so you can use it to triple check the results from Beider-Morse Phonetic Matching and the Rosette API.
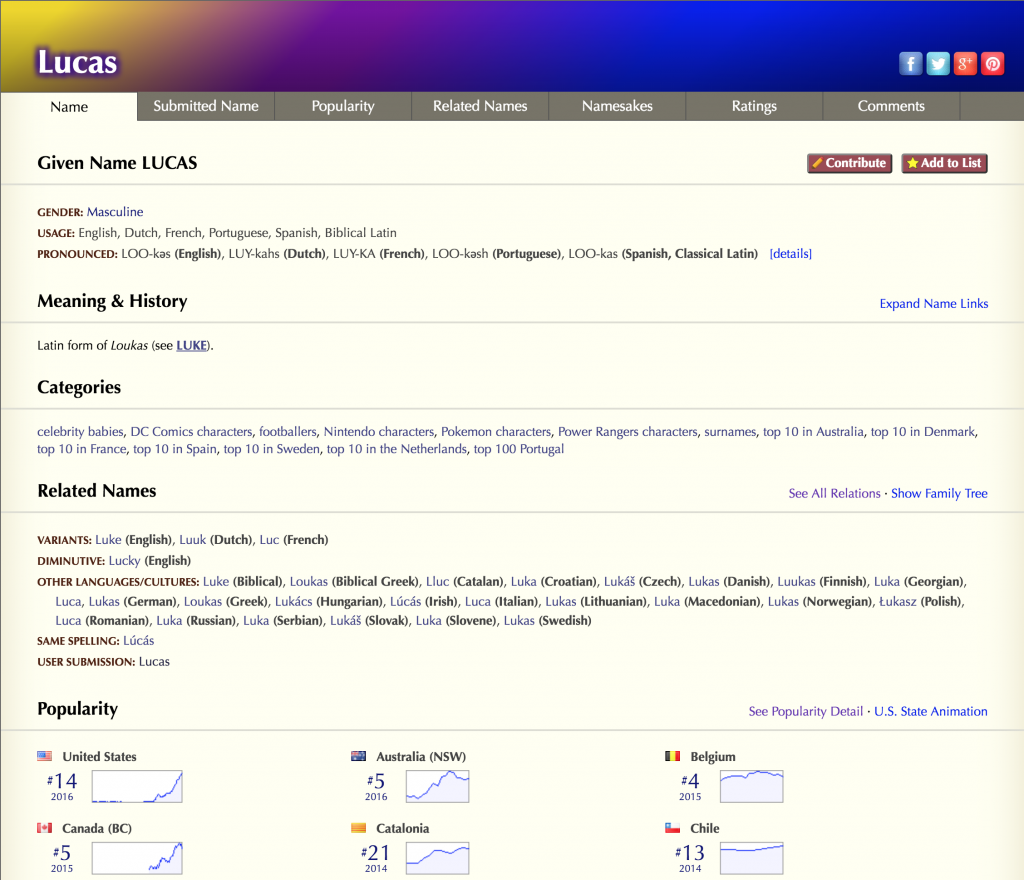
Adding it all Together
Lets just add this to our previous Java 8 Streams filter:
| .filter(n -> NameUtils.isInLanguage(n, "english"))
.filter(n -> NameUtils.isInLanguage(n, "spanish"))
.filter(n -> NameUtils.soundsLikeLanguage(n, "english"))
.filter(n -> NameUtils.soundsLikeLanguage(n, "spanish")) .filter(name -> NameUtils.sameTranslationAsLanguage(name, ENGLISH))
//.filter(name -> NameUtils.sameTranslationAsLanguage(name, SPANISH)) // They don't support Spanish
.filter(name -> NameUtils.existsInLanguages(name, "por", "eng", "spa")) ; |
Final Results
After all, rules are applied and filtered the initial list, only 2 names remained. One is the obvious Lucas and the other was David. So, both these names exist, are written and are pronounced in the same way for Portuguese, English, and Spanish.
Proof it works?
Well, now I’ve just go to any random Starbucks and something with the name Lucas and confirm that they got it right. So far so good!

If you find this interesting, I even published the code in a Github repo. Check it out.
Note for Lucas: Lucas if you read this when your older, please excuse me for having such a geeky father.
In one way or another, every developer has come in touch with an API. Either integrating a major system for a big corporation, producing some fancy charts with the latest graph library, or simply by interacting with his favorite programming language. The truth is that APIs are everywhere! They actually represent a fundamental building block of the nowadays Internet, playing a fundamental role in the data exchange process that takes place between different systems and devices. From the simple weather widget on your mobile phone to a credit card payment you perform on an online shop, all of these wouldn’t be possible if those systems wouldn’t communicate with each other by calling one another’s APIs.
So with the ever growing eco-system of heterogeneous devices connected to the internet, APIs are put a new set of demanding challenges. While they must continue to perform in a reliable and secure manner, they must also be compatible with all these devices that can range from a wristwatch to the most advanced server in a data-center.
REST to the rescue
One of the most widely used technologies for building such APIs are the so called REST APIs. These APIs aim to provide a generic and standardize way of communication between heterogeneous systems. Because they heavily rely on standard communication protocols and data representation – like HTTP, XML or JSON – it’s quite easy to provide client side implementations on most programming languages, thus making them compatible with the vast majority of systems and devices.
So while these REST APIs can be compatible with most devices and technologies out there, they also must evolve. And the problem with evolution is that you sometimes have to maintain retro-compatibility with old client versions.
Let’s build up an example.
Let’s imagine an appointment system where you have an API to create and retrieve appointments. To simplify things let’s imagine our appointment object with a date and a guest name. Something like this:
| public class AppointmentDTO { public Long id; public Date date; public String guestName; } |
A very simple REST API would look like this:
| @Path("/api/appointments") public class AppointmentsAPI { @GET @Path("/{id}") public AppointmentDTO getAppointment(@PathParam("id") String id) { ... } @POST public void createAppointment(AppointmentDTO appointment) { ... } } |
Let’s assume this plain simple API works and is being used on mobile phones, tablets and various websites that allow for booking and displaying appointments. So far so good.
At some point, you decide it would be very interesting to start gathering some statistics about your appointment system. To keep things simple you just want to know who’s the person who booked most times. For this you would need to correlate guest between themselves and decide you need to add an unique identifier to each guest. Let’s use Email. So now your object model would look like something like this:
| public class AppointmentDTO { public Long id; public Date date; public GuestDTO guest; } public class GuestDTO { public String email; public String name; } |
So our object model changed slightly which means we will have to adapt the business logic on our api.
The Problem

While adapting the API to store and retrieve the new object types should be a no brainer, the problem is that all your current clients are using the old model and will continue to do so until they update. One can argue that you shouldn’t have to worry about this, and that customers should update to the newer version, but the truth is that you can’t really force an update from night to day. There will always be a time window where you have to keep both models running, which means your api must be retro-compatible.
This is where your problems start.
So back to our example, in this case it means that our API will have to handle both object models and be able to store and retrieve those models depending on the client. So let’s add back the guestName to our object to maintain compatibility with the old clients:
| public class AppointmentDTO { public Long id; public Date date; @Deprecated //For retro compatibility purposes public String guestName; public GuestDTO guest; } |
Remember a good thumb rule on API objects is that you should never delete fields. Adding new ones usually won’t break any client implementations (assuming they follow a good thumb rule of ignoring new fields), but removing fields is usually a road to nightmares.
Now for maintaining the API compatible, there are a few different options. Let’s look at some of the alternatives:
- Duplication: pure and simple. Create a new method for the new clients and have the old ones using the same one.
- Query parameters: introduce a flag to control the behavior. Something like useGuests=true.
- API Versioning: Introduce a version in your URL path to control which method version to call.
So all these alternatives have their pros and cons. While duplication can be plain simple, it can easily turn your API classes into a bowl of duplicated code.
Query parameters can (and should) be used for behavior control (for example to add pagination to a listing) but we should avoid using them for actual API evolutions, since these are usually of a permanent kind and therefore you don’t want to make it optional for the consumer.
Versioning seems like a good idea. It allows for a clean way to evolve the API, it keeps old clients separated from new ones and provides a generic base from all kinds of changes that will occur during your API lifespan. On the other hand it also introduces a bit of complexity, specially if you will have different calls at different versions. Your clients would end up having to manage your API evolution themselves by upgrading a call, instead of the API. It’s like instead of upgrading a library to the next version, you would upgrade only a certain class of that library. This can easily turn into a version nightmare…
To overcome this we must ensure that our versions cover the whole API. This means that I should be able to call every available method on /v1 using /v2. Of course that if a newer version on a given method exists on v2 it should be run on the /v2 call. However, if a given method hasn’t changed in v2, I expect that the v1 version would seamlessly be called.
Inheritance based API Versioning
In order to achieve this we can take advantage of Java objects polymorphic capabilities. We can build up API versions in a hierarchical way so that older version methods can be overridden by newer, and calls to a newer version of an unchanged method can be seamlessly fallen back to it’s earlier version.
So back to our example we could build up a new version of the create method so that the API would look like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | @Path("/api/v1/appointments") //We add a version to our base path public class AppointmentsAPIv1 { //We add the version to our API classes @GET @Path("/{id}") public AppointmentDTO getAppointment(@PathParam("id") String id) { ... } @POST public void createAppointment(AppointmentDTO appointment) { //Your old way of creating Appointments only with names } } //New API class that extends the previous version @Path("/api/v2/appointments") public class AppointmentsAPIv2 extends AppointmentsAPIv1 { @POST @Override public void createAppointment(AppointmentDTO appointment) { //Your new way of creating appointments with guests } } |
So now we have 2 working versions of our API. While all the old clients that didn’t yet upgrade to the new version will continue to use v1 – and will see no changes – all your new consumers can now use the latest v2. Note that all these calls are valid:
| Call | Result |
|---|
|
GET /api/v1/appointments/123 | Will run getAppointment on the v1 class |
|
GET /api/v2/appointments/123 | Will run getAppointment on the v1 class |
|
POST /api/v1/appointments | Will run createAppointment on the v1 class |
|
POST /api/v2/appointments | Will run createAppointment on the v2 class |
This way any consumers that want to start using the latest version will only have to update their base URLs to the corresponding version, and all of the API will seamlessly shift to the most recent implementations, while keeping the old unchanged ones.
Caveat
For the keen eye there is an immediate caveat with this approach. If your API consists of tenths of different classes, a newer version would imply duplicating them all to an upper version even for those where you don’t actually have any changes. It’s a bit of boiler plate code that can be mostly auto-generated. Still annoying though.
Although there is no quick way to overcome this, the use of interfaces could help. Instead of creating a new implementation class you could simply create a new Path annotated interface and have it implemented in your current implementing class. Although you would sill have to create one interface per API class, it is a bit cleaner. It helps a little bit, but it’s still a caveat.
Final thoughts
API versioning seems to be a current hot topic. Lot of different angles and opinions exists but there seems to be a lack of standard best practices. While this post doesn’t aim to provide such I hope that it helps to achieve a better API structure and contribute to it’s maintainability.
A final word goes to Roberto Cortez for encouraging and allowing this post on his blog. This is actually my first blog post so load the cannons and fire at will. 😉
Annotations became available with Java 1.5 in 2004, ten years ago. It’s hard to imagine our code without this feature. In fact, annotations were first introduced to relieve developers from the pain of writing tedious boilerplate code and make the code more readable. Think about J2EE 1.4 (no annotations available) and Java EE 5. Annotation adoption considerably simplified the development of a Java EE application by getting rid of all the configuration XML. Even today, more annotations are being added to the newest version of Java EE. The idea is to unburden the developer and increase productivity. Other technologies and frameworks use them extensively as well.

Annotations Everywhere
Let’s see an example on how annotations have simplified our code (from my post about JPA Entity Graphs):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | @Entity @Table(name = "MOVIE_ENTITY_GRAPH") @NamedQueries({ @NamedQuery(name = "Movie.findAll", query = "SELECT m FROM Movie m") }) @NamedEntityGraphs({ @NamedEntityGraph( name = "movieWithActors", attributeNodes = { @NamedAttributeNode("movieActors") } ), @NamedEntityGraph( name = "movieWithActorsAndAwards", attributeNodes = { @NamedAttributeNode(value = "movieActors", subgraph = "movieActorsGraph") }, subgraphs = { @NamedSubgraph( name = "movieActorsGraph", attributeNodes = { @NamedAttributeNode("movieActorAwards") } ) } ) }) public class Movie implements Serializable { @Id private Integer id; @NotNull @Size(max = 50) private String name; @OneToMany @JoinColumn(name = "ID") private Set<MovieActor> movieActors; @OneToMany(fetch = FetchType.EAGER) @JoinColumn(name = "ID") private Set<MovieDirector> movieDirectors; @OneToMany @JoinColumn(name = "ID") private Set<MovieAward> movieAwards; } |
Wait a minute! Simplified? Really? Aren’t annotations supposed to make my code more readable? This example has more annotations than actual code. To be fair, I’m not including getters and setters. Also, some of the annotated code could be better condensed, but it would make the code harder to read. Of course, this is an extreme case. Anyway, I’m happy since I won the title Annotatiomaniac of the Year. Thanks Lukas!

We rely in annotations so much that we end up abusing them. It’s funny that annotations in some cases are causing the same problems that they intended to solve.
What if?
Let’s rewrite the previous sample like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | @MovieEntity @FindAll @LoadWithActors @LoadWithActorsAndAwards public class Movie implements Serializable { @Id private Integer id; @Name private String name; @MovieActors private Set<MovieActor> movieActors; @MovieDirectors private Set<MovieDirector> movieDirectors; @MovieAwards private Set<MovieAward> movieAwards; } |
It sure looks more readable. But these annotations do not exist. Where do they come from?
@LoadWithActors
| @NamedEntityGraph( name = "movieWithActors", attributeNodes = { @NamedAttributeNode("movieActors") } ) public @interface LoadWithActors {} |
@LoadWithActorsAndAwards
| @NamedEntityGraph( name = "movieWithActorsAndAwards", attributeNodes = { @NamedAttributeNode(value = "movieActors", subgraph = "movieActorsGraph") }, subgraphs = { @NamedSubgraph( name = "movieActorsGraph", attributeNodes = { @NamedAttributeNode("movieActorAwards") } ) } ) public @interface LoadWithActorsAndAwards {} |
And so on for the rest. You get the feeling. The idea would be to extract and group annotation metadata into your own custom annotations. Your annotation could then be used to represent all the annotated data in your code, making it easier to understand. It’s like Java 8 Lambdas, read like the problem statement.
Just another example:
| @Named @Stateless @TransactionAttribute(TransactionAttributeType.SUPPORTS) @ApplicationPath("/resources") @Path("wowauctions") @Consumes(MediaType.APPLICATION_JSON) @Produces(MediaType.APPLICATION_JSON) public class WoWBusinessBean extends Application implements WoWBusiness {} |
Rewritten:
| @RestStatelessBean("wowauctions") public class WoWBusinessBean extends Application implements WoWBusiness {} |
@RestStatelessBean
| @Named @Stateless @TransactionAttribute(TransactionAttributeType.SUPPORTS) @ApplicationPath("/resources") @Path("#{path}") @Consumes(MediaType.APPLICATION_JSON) @Produces(MediaType.APPLICATION_JSON) public @interface RestStatelessBean { String value() default "#{path}"; } |
Usually, I write these annotations once to define the behaviour of my POJO and never look into them again. How cool would be if I could just reuse one annotation for all my Stateless Rest Services?
Another nice effect, is that annotation configuration metadata is not directly tied in the code. Instead it’s abstracted away into a different annotation. In this case, it would be possible to override or replace the values in compile / runtime.
Meta Annotations
I first heard about this concept by David Blevins. He wrote a very good post about these ideas in his Meta-Annotations post and even wrote a possible implementation.
It would be convenient to have plain Java SE support to annotation inheritance, abstraction and encapsulation. It’s a major shift in the way annotations are handled by all the technologies out there. This only makes sense if everyone starts supporting this kind of behaviour.
One might ask, do we really need this feature? Let’s try to weigh in some pros and cons:
Pros
- Simplified Code.
- Annotation Reuse.
- Annotation configuration not directly tied to the code. Values could be overridden.
Cons
- Another layer of abstraction.
- Freedom to create custom annotations could obfuscate the real behaviour.
- Possible to run into some kind of multiple inheritance pitfall.
Conclusion
It’s unlikely that this Meta-Annotations are going to be available in Java SE for the foreseeable future. In Java 9, most of the focus is in Jigsaw. We don’t have much information yet on Java 10, other than Value Types and Generic Specialization. In fact, all these annotation concerns are not really a problem for plain Java SE.
The amount of annotations present in our source files is becoming a problem regarding readability and maintainability. This is especially true for Java EE and other similar technologies. Think about HTML and CSS. If you’re developing an HTML page and you only need a couple of CSS styles, you usually inline them in the elements or include them directly in the page. If you start to have too many styles, then you proceed to extract them into an external CSS file and just apply the style. I do believe that something must be done either by adopting Meta-Annotations or something else. Do you have any other ideas? Please share them!
Resources
Don’t forget to check David Blevins post about Meta-Annotations. He explains this much better than me, including the technical details.
Also a presentation JavaOne EJB with Meta Annotations discussing these ideas by David Blevins.
And what better than to listen David Blevins himself? Java EE 7, Infinite Extensibility meets Infinite Reuse.
Last Wednesday, 16 July 2014, the fifth meeting of Coimbra JUG was held on the Department of Informatics Engineering of the University of Coimbra, in Portugal. The attendance was very good, we had around 30 people to listen João Antunes talk about the Web Framework – Spring MVC. A very special thanks to João for taking the challenge and steer the session.
This topic continues a long list of Web Frameworks planned to be presented at Coimbra JUG. Have a look into the most wanted sessions pool, and cast your vote if you’re a member.

I did a quick introduction about Coimbra JUG for the newcomers and João dived right into the session about Spring MVC. Spring MVC is not exactly a new technology, but only one or two attendees were using it. The rest of the attendees seemed very curious and interested to learn about it.
Looking into Rebellabs – Java Tools and Technologies Landscape for 2014, Spring MVC appears at 1st place for the Web Frameworks in use with a 40% share. A huge percentage, which means that is very likely for you to como across with it in the future.
As always, we had surprises for the attendees: beer and chocolates, if you participated in the discussion. IntelliJ sponsored our event, by offering a free license to raffle among the attendees. Congratulations to João Baltazar for winning the license. Develop with pleasure! We also offered the book The Definitive Guide to HTML5 WebSocket courtesy of Kaazing, congratulations to Jessica Vicente. Finally, we gave away two Atlassian Stash t-shirs: “Just Do GIT” to Mário Homem and João Almeida.
Here are the materials for the session:
Enjoy!
