Yes, Java helped me name Lucas
 Having a child is one of the most memorable moment you can experience. Parents have a huge responsibility with this new life and it starts right away when they have to choose the name. Our name is something that we keep for life (most of the times), so it needs some careful consideration. With literally thousands of names to choose from, how about using some Java technology to help us?
Having a child is one of the most memorable moment you can experience. Parents have a huge responsibility with this new life and it starts right away when they have to choose the name. Our name is something that we keep for life (most of the times), so it needs some careful consideration. With literally thousands of names to choose from, how about using some Java technology to help us?
Yes, I wrote a small Java application to help me choose my baby name!
Requirements
First of all, we have to define some rules!
Basic Rules
- A short name (but not too short)
- In the first half of the alphabet
- Without special characters
A short name, so it easy to call him. In the first half of the alphabet, because in Portugal we have this stupid rule where kids get seated in the classrooms in alphabetic order, so letters in the end of the alphabet get to sit in the end of the room! And finally, a name without special characters (we have a few in Portugal), to be easier for foreign people to use.
Advanced Rules
- Exists in at least three languages (Portuguese, Spanish and English)
- Sounds and Writes the same in all three languages
To cover the fact that I was born in a Spanish speaking country, that we live in Portugal and English for the globalization.
Constraints
There are also some constraints. In Portugal, you cannot use any name you want. You need to pick the name from an approved list of names. Of course, this is a comprehensive list of names that covers all common names. It is mostly used to avoid giving a stupid name to your kid. If your curious about it, check the list here.
Implementation
Basic Rules are Easy
After grabbing the data in the file and use some Java 8 Streams:
1 2 3 4 5 6 | .filter(Name::isAllowed)
.filter(Name::isNotFemale)
.filter(Name::withoutSpecialChars)
.filter(n -> n.between(3, 7))
.filter(n -> n.notStarstWith("N", "O","P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z")) ; |
(Yes, I’m lazy with regular expressions)
Advanced Rules are more Interesting
Beider-Morse Phonetic Matching
When searching for a way to determine if a word or a name exists in another language and sounds the same, I came across with the Beider-Morse Phonetic Matching.
The main objective of Beider-Morse Phonetic Matching consists in recognizing that two words are written in a different way actually can be phonetically equivalent, that is, they both can sound alike. But unlike soundex methods, the “sounds-alike” test is based not only on the spelling but on linguistic properties of various languages.
How?
It tries to guess the language of the word following specific language rules and then calculates a phonetic value for that word. For instance:
- tsch, final mann and witz are specifically German
- final and initial cs and zs are necessarily Hungarian
- cz, cy, initial rz and wl, final cki, letters ś, ł and ż can be only Polish
And then a phonetic value is calculated:
| Original | Phonetic Value | Example |
|---|---|---|
| tz | ts | Fitzgerald |
| c | s | circle |
| cc | ks | success,accent |
| gh | (g|f|w) | burgh|tough|bough |
| kn | n | knight |
| mc | mak | McDonald |
The Commons Coded project has an implementation of the Beider-Morse Phonetic Matching algorithm. Try it out and play with it.
Rosette API
The Rosette API is a Text Analysis Toolkit, that provides multiple services to perform text analysis. They also have a Name Translation service with a REST endpoint that you can use to feed in names and the desired language and return the right translation with a confidence score. Their API is useful to double check results obtained with the Beider-Morse Phonetic Matching.
They have fantastic support, providing libraries to integrate with their API’s in multiple languages and also a lot of samples you can use. Check their Github repo here.
behindthename.com
The Behind the Name website provided with the etymology and history of first names, plus a comprehensive list of names and what languages do they exist. On top of that, they also provide an API to check that information, so you can use it to triple check the results from Beider-Morse Phonetic Matching and the Rosette API.
Adding it all Together
Lets just add this to our previous Java 8 Streams filter:
1 2 3 4 5 6 7 8 | .filter(n -> NameUtils.isInLanguage(n, "english"))
.filter(n -> NameUtils.isInLanguage(n, "spanish"))
.filter(n -> NameUtils.soundsLikeLanguage(n, "english"))
.filter(n -> NameUtils.soundsLikeLanguage(n, "spanish")) .filter(name -> NameUtils.sameTranslationAsLanguage(name, ENGLISH))
//.filter(name -> NameUtils.sameTranslationAsLanguage(name, SPANISH)) // They don't support Spanish
.filter(name -> NameUtils.existsInLanguages(name, "por", "eng", "spa")) ; |
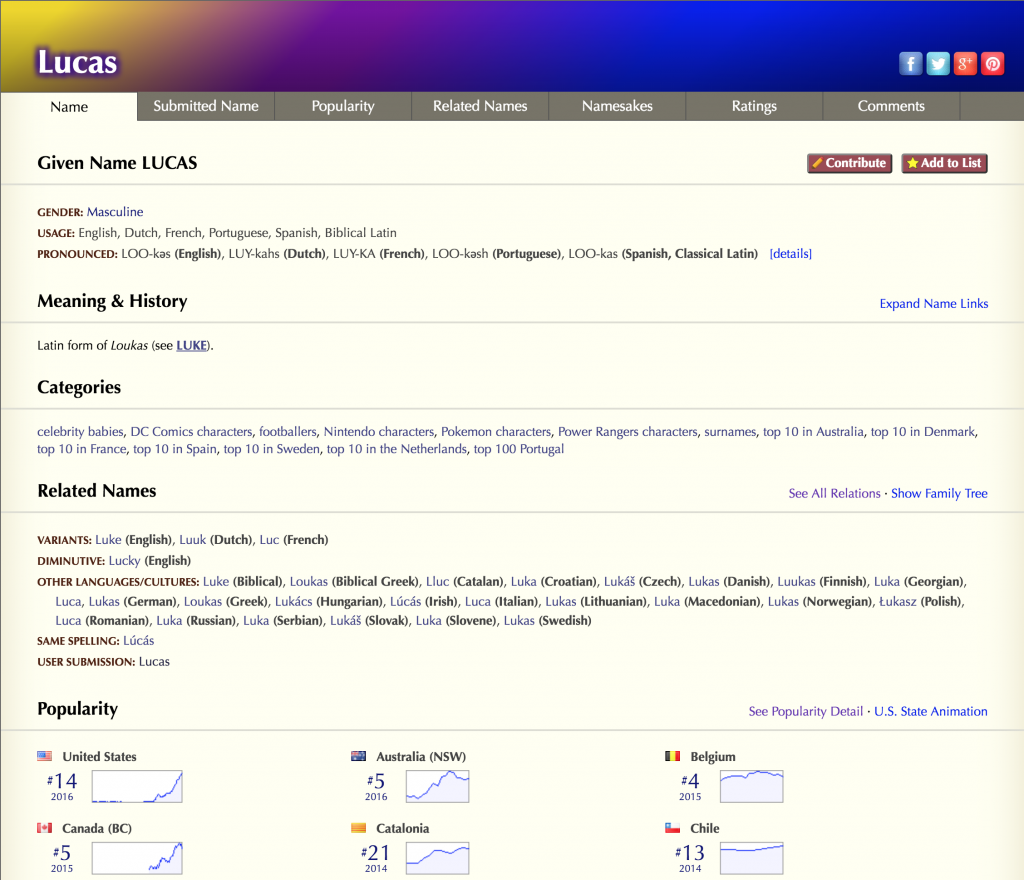
Final Results
After all, rules are applied and filtered the initial list, only 2 names remained. One is the obvious Lucas and the other was David. So, both these names exist, are written and are pronounced in the same way for Portuguese, English, and Spanish.
Proof it works?
Well, now I’ve just go to any random Starbucks and something with the name Lucas and confirm that they got it right. So far so good!

If you find this interesting, I even published the code in a Github repo. Check it out.
Note for Lucas: Lucas if you read this when your older, please excuse me for having such a geeky father.